
Why Small Language Models Are Set to Steal the Spotlight in Agentic AI
A deep dive into NVIDIA's bold paper claiming SLMs are the real MVPs for AI agents—cheaper, faster, and better.

Okay, let's be real—AI agents are exploding right now. They're the bots handling your emails, coding up fixes, or even managing your smart home without you lifting a finger. Or maybe there are not and is just hype. But here's the kicker: most of these agents are powered by massive large language models (LLMs) like those beasts from OpenAI or Google or Anthropic or Meta, eating energy and cash like there's no tomorrow.
Enter a fresh paper from NVIDIA Research, dropped recently, arguing that small language models (SLMs)—think models under 10 billion parameters that can run on your laptop—are actually the future of this agentic AI boom. Full disclosure: I'm no NVIDIA insider, but as someone who's been watching out over AI trends closely (remember my post on Capgemini's Resonance AI?), this paper hit me. It's not just tech talk; it's a wake-up call on why we might be overpaying for AI software (agents) we don't fully need. It’s like buying a Ferrari to go go grocery shopping few blocks away. Buckle up, because we're unpacking this short summary in my usual style—analogies, real talk, and a dash of "what ifs".
The paper, titled "Small Language Models are the Future of Agentic AI," is penned by a team of NVIDIA brains like Peter Belcak and Pavlo Molchanov, plus a Georgia Tech collab. It's a position piece, not some dry experiment log—think manifesto for ditching LLMs in favor of SLMs for most agent work. They back it with stats, examples, and even a how-to guide for switching over.
Why care? Agentic AI is already a multi-billion-dollar beast, with surveys showing over half of big IT firms using agents, and markets predicting it'll balloon to $200 billion by 2034. And every tech consulting firm screaming we can build & help!
But the current setup? Agents ping huge LLMs in the cloud for every little task, burning through billions in infrastructure. The authors say that's wasteful—SLMs can handle the grunt work better, cheaper, and greener. NVIDIA's take on SLMs in agentic AI. (Imagine a cool graphic here of a tiny model zipping past a hulking LLM—source: the paper's Figure 1, but I'll describe it later.)
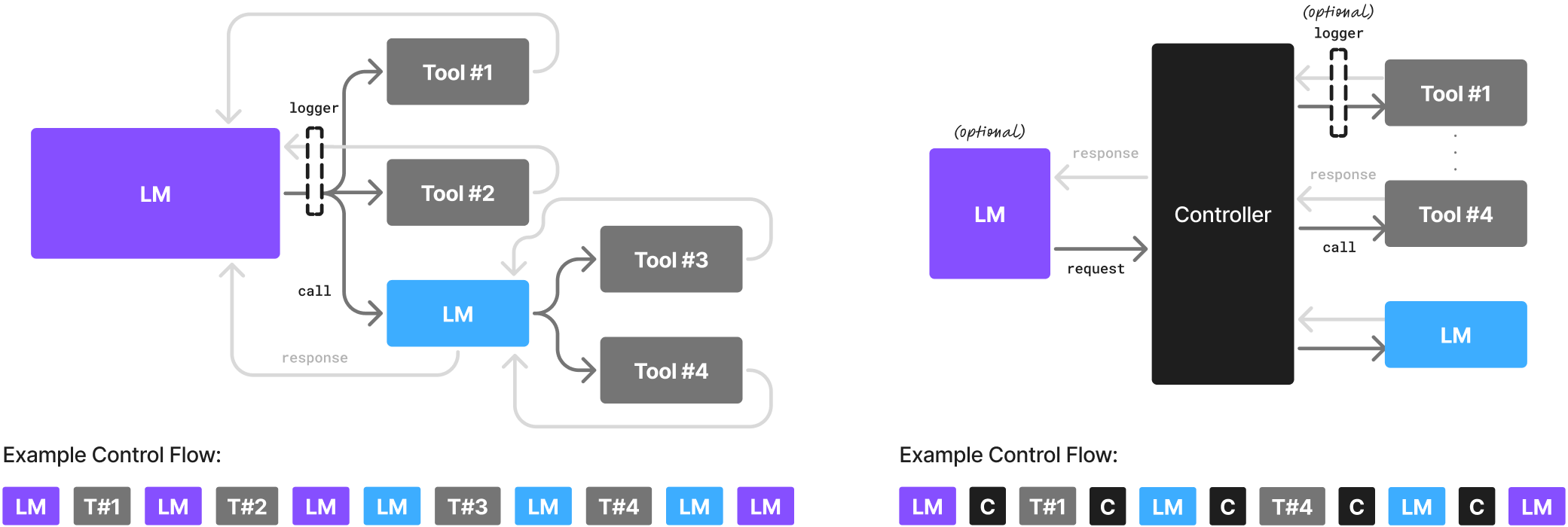
What's the Big Idea? Defining SLMs and the Position First off, they define SLMs simply: models small enough to fit on your phone or laptop, cranking out responses fast for one user without lagging.
Anything bigger? That's an LLM, stuck in data centers. As of 2025, that's mostly under 10B params—tiny compared to GPT-4's rumored hundreds of billions.
Their core stance: SLMs are powerful enough for most agent tasks, more operationally fitting, and way more economical. They call it a "value statement," not a bossy recommendation—basically, if we follow logic and priorities like cost and efficiency, SLMs win. Agents break down big jobs into repetitive subtasks: planning, tool-calling, reasoning in loops. Why waste a generalist LLM on that when a tuned SLM nails it? For chatty, open-ended stuff, mix them in heterogeneous systems—SLMs for the basics, LLMs as the big queries when needed.
They elaborate: LLMs are overkill for agents' narrow, scripted interactions. Agents aren't chit-chatting philosophy; they're parsing code, calling APIs, or summarizing docs. SLMs shine here with lower latency, less power draw, and easier tweaks. Plus, it's sustainable—leaving LLM monoliths could slash AI's carbon footprint. They nod to philosophy too: it's a "Humean moral ought," meaning if we value efficiency and the planet, we should shift.
The Arguments: Why SLMs Rock for Agents
The meat of the paper? A bunch of arguments backing their views. Let's break them down like I did with Capgemini's pillars—step by step, no jargon overload.
Argument 1: SLMs Are Already Beast-Mode Capable.
Forget the old "bigger is better" trope. Scaling laws say more params equal more smarts, but recent SLMs bend that curve. Examples? Microsoft's Phi-3 (7B params) matches 70B models on reasoning and code gen, running 15x faster. NVIDIA's own Nemotron-H (up to 9B) rivals 30B LLMs at a fraction of the compute. Hugging Face's SmolLM2 (1.7B) punches like 14B contemporaries. DeepSeek's distilled models even beat GPT-4o on commonsense. Add tricks like tool augmentation or self-consistency, and a 3B SLM solves math like a 30B one. Bottom line: For agent errands like tool-calling or instruction-following, SLMs deliver without the bloat.
Argument 2: Cheaper Than a Budget Lunch. Inference on a 7B SLM?
10-30x less in energy, FLOPs, and cash than a 175B LLM. Fine-tuning? Hours, not weeks. Edge deployment? Run them offline on your GPU with stuff like NVIDIA's ChatRTX. LLMs waste params on sparse signals; SLMs are denser, more efficient. Modular agents? Stack SLMs like Legos for specialized tasks—cheaper to debug, deploy, and scale.
Argument 3: Flexibility on Steroids.
SLMs cost less to train or tweak, so spin up experts for niche jobs. This democratizes AI—more folks can build agents, fostering diversity and innovation. No more one-size-fits-all.
Argument 4: Agents Barely Scratch LLM Surfaces.
Agents cage LLMs with prompts and tools, using like 10% of their skills. A fine-tuned SLM for that narrow slice? Just as good, plus bonuses.
Argument 5: Alignment Matters Big Time.
Agents chat with code—tool calls need perfect formatting (JSON, not YAML). SLMs, tuned for one style, hallucinate less and fit seamlessly.
Argument 6: Heterogeneity is Baked In.
Agents can call multiple models. Use an LLM for the boss-level planning, SLMs for minions. Or go full SLM with a chatty one for users and specialists for backend.
Argument 7: Free Data Goldmine.
Agent interactions spit out perfect fine-tuning data. Log them (ethically), curate, and boom—better SLMs over time.
These aren't exhaustive, but they paint a picture: SLMs aren't underdogs; they're optimized for the agent game.
But Wait, Counterarguments?
They Tackle Them Head-On: No paper's complete without pushback. They address alternatives like "LLMs always win on language understanding" (scaling laws say so, plus some "semantic hub" theory). But: New architectures close the gap, fine-tuning fixes niches, and agents decompose tasks anyway—no hub needed for simple subtasks.
Another: Centralized LLMs are cheaper at scale. Maybe, but modular inference tech is catching up, and setup costs are dropping.
They admit inertia—LLMs have a head start—but argue advantages will flip it.
Barriers: Why Aren't We There Yet?
Honest talk: Billions sunk into LLM clouds, benchmarks favoring generalists, and SLMs lacking hype. But these are fixable—better scheduling, agent-focused evals, and word-of-mouth on savings.
The Fix: LLM-to-SLM Conversion Recipe
1. Log agent calls (anonymized, secure).
2. Curate data—scrub sensitive stuff, paraphrase if needed.
3. Cluster tasks (e.g., summarization, code gen).
4. Pick SLMs (Phi, Mistral as starters).
5. Fine-tune with LoRA or distillation.
6. Iterate with fresh data.
It's like upgrading your car engine without buying a new ride—painless, iterative.
What’s next?
Build Small Language Models. It's about making AI cheaper and greener to speed up the agent revolution.
My Two Cents: Is This the Future? As someone who's seen AI hype cycles (hello, model collapse fears), this paper feels spot-on. Agents are repetitive workhorses, not philosophers—SLMs fit like gloves. Imagine: Cheaper agents mean more access, from startups to your grandma's recipe bot. But risks? Fine-tuning could amplify biases if data's junky, and heterogeneity might complicate debugging. What's next? Multimodal SLMs for vision agents? On-device privacy wins? Or pushback from LLM giants? I'm betting SLMs surge, especially with energy costs rising. What do you think? Will SLMs dethrone LLMs in agents, or is it hype? Drop a comment—let's keep the AI convo rolling.